The Intelligence Layer for
LLM Applications
Monitor, optimize, and secure your AI applications in production. Built for developers who ship fast and scale with confidence.
Built for production scale
Enterprise-grade infrastructure from day one
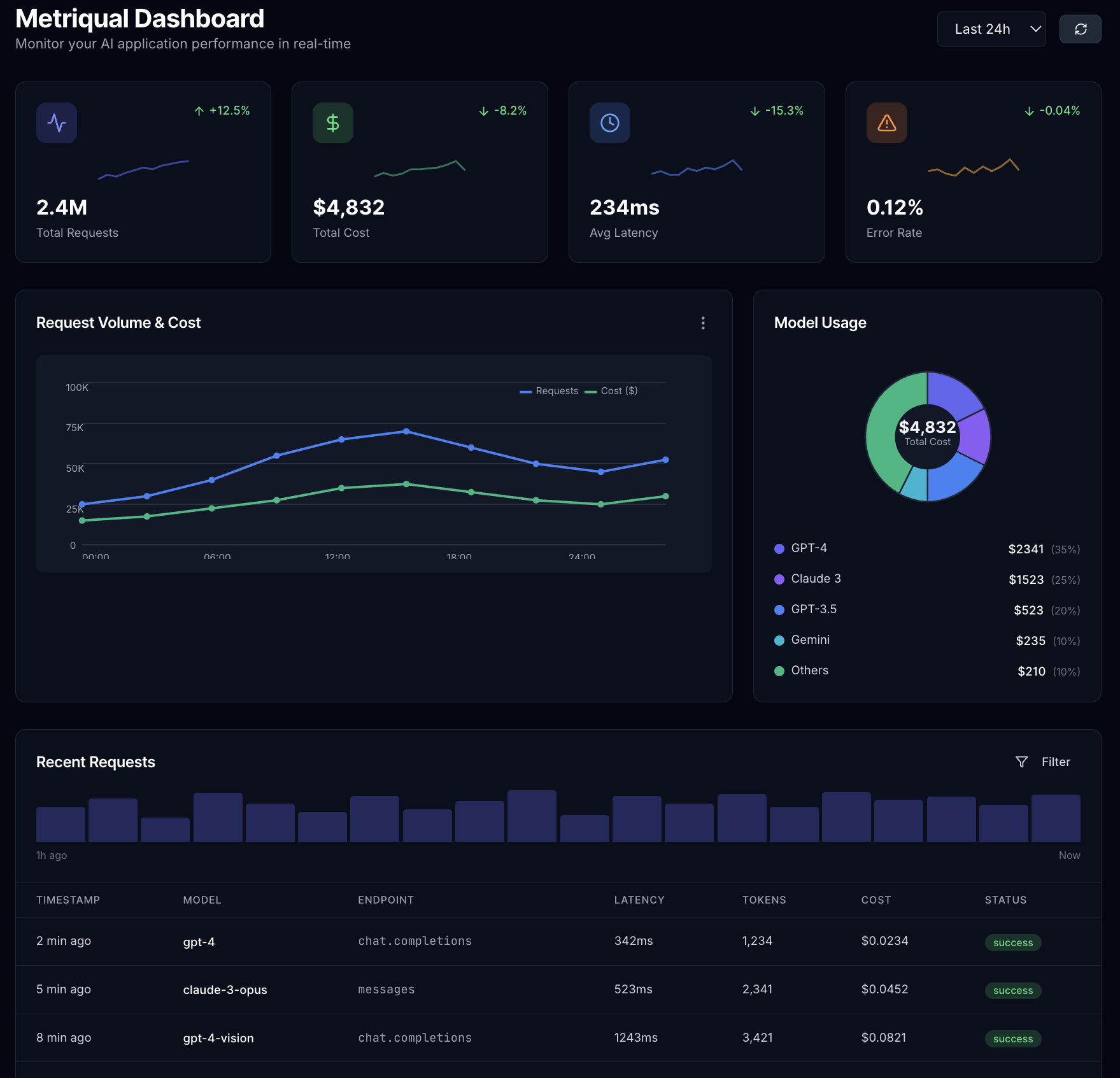
Everything you need to ship with confidence
Everything you need to build reliable AI
A comprehensive platform that handles observability, quality, security, and scale - so you can focus on building great AI products.
Real-time Monitoring
Track every LLM call with sub-millisecond precision. Monitor latency, tokens, costs, and errors across all providers.
// Real-time monitoring
const response = await metriqual.chat.create({
model: "gpt-4",
messages: [...]
})
// Automatic tracking:
// ✓ Latency: 342ms
// ✓ Tokens: 1,234
// ✓ Cost: $0.0234
// ✓ Provider: OpenAIWorks with your entire stack
Drop-in integration with every major LLM provider, framework, and tool. No vendor lock-in, no complicated setup.
LLM Providers
Frameworks
Infrastructure
Developer Tools
One SDK, all providers
Use the same clean API across all LLM providers. Switch models with a single parameter change. No more managing different SDKs and response formats.
// Same API for all providers
const response = await metriqual.chat.create({
// Just change the model
model: "gpt-4", // OpenAI
// model: "claude-3", // Anthropic
// model: "gemini-pro", // Google
// model: "mixtral", // Mistral
messages: [{
role: "user",
content: "Explain quantum computing"
}]
})
// Automatic tracking for all providers
console.log(response.metrics)
// {
// latency: 234,
// tokens: 567,
// cost: 0.023,
// provider: "openai"
// }Built for developers, by developers
Clean APIs, comprehensive SDKs, and documentation that actually helps. Get started in minutes, not days.
# Install Metriqual
pip install metriqual
# Initialize the client
from metriqual import Metriqual
client = Metriqual(api_key="your-api-key")
# Make any LLM call - we handle the rest
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Hello!"}]
)
# Access metrics instantly
print(f"Cost: ${response.metrics.cost}")
print(f"Latency: {response.metrics.latency}ms")
print(f"Tokens: {response.metrics.tokens}")Intuitive CLI
Manage everything from your terminal. Deploy prompts, view logs, analyze costs.
Type Safety
Full TypeScript support with autocompletion. Know exactly what you're working with.
Great Docs
Comprehensive guides, API references, and real examples that actually work.
Powering AI at every scale
From startups to enterprises, teams use Metriqual to build reliable, cost-effective AI applications that users trust.
Customer Support AI
Monitor response quality, detect hallucinations, and ensure consistent support across thousands of conversations.
AI Agents & Assistants
Track complex multi-step workflows, optimize routing between models, and ensure reliable autonomous operations.
RAG Applications
Monitor retrieval quality, track embedding costs, and optimize the balance between context and generation.
Content Moderation
Detect toxic content, ensure compliance, and maintain brand safety across all generated content.
Enterprise Automation
Scale AI across departments with governance, monitor compliance, and track ROI on AI investments.
Real-time Applications
Optimize for speed with intelligent caching, model selection, and geographic routing.
Ready to build reliable AI?
Join thousands of teams shipping better AI products with Metriqual. Start monitoring, optimizing, and scaling your LLM applications today.
Join the next generation of AI builders. Start monitoring in minutes.